
티스토리 뷰
T-SNE 를 본격적으로 다루기 전에 SNE에 대해서 설명합니다.¶
1. Introduction¶
1-1 높은 차원의 데이터시각화¶
높은 차원의 데이터를 시각화 하는 것은 여러 도메인에서 매우 중요한 문제이며 다양한 차원의 데이터를 다룹니다.
예를 들면 아래와 같은 다양한 경우가 있을 수 있습니다.
- 의료: breast cancer와 관련 있는 세포핵은 약 30개의 변수 데이터로 표현됨
- 이미지: 이미지를 표현하기 위해서 각 픽셀마다의 벡터(W*H) 로 표현됨
텍스트: Document를 표현하기 위해서 Word counting 방법을 통해 수만개의 변수로 표현됨

높은 차원의 데이터 시각화를 위해서 많은 기법이 제시되었지만 기존의 방법은 다음과 같은 단점들이 있습니다.
- 사람의 해석을 필요로 한다
- 2차원 이상의 차원으로 매핑한다.
사람에게 할일을 떠넘기는 기존의 방식은 몇천개가 넘어가는 수의 매우 높은 차원을 가진 데이터를 분석할 때 문제가 있을 수 있습니다
1-2 dimensionality reduction¶
기존에 PCA등 dimensionality reducntion 방법을 알고 계신다면 "왜 그것을 그냥 적용하면 안 될까?" 의문을 가질 수 있습니다.
기존의 dimensionality reducntion 은 매우 powerful하고 성공적인 성능을 보여주고 있지만 시각화에서는 그 성능이 뛰어나지 않습니다.
시각화에는 기존 dimensionality reducntion 방법을 기대로 적용하기에는 무리가 있습니다.
특히,대부분의 차원 축소 기술들은 데이터의 global 및 local structure 정보를 한개의 map(한개의 좌표 평면인듯?)에 매핑하는 능력이 부족합니다.
1-3 본 논문의 주된 내용¶
- high dimensional data set를 각 데이터 포인트 간의 similarity를 나타낼 수 있는 matrix로 나타낼 수 있는 기존의 방법을 기술합니다.
- 새로운 proposed method인“t-SNE”라고 불리는 similarity matrix 결과를 시각화 할 수 있는 방법을 제시합니다. t-sne는 local 과 global정보를 모두 파악하며 시각화 가능 합니다.

1-4 local glbal 정보를 파악함?¶
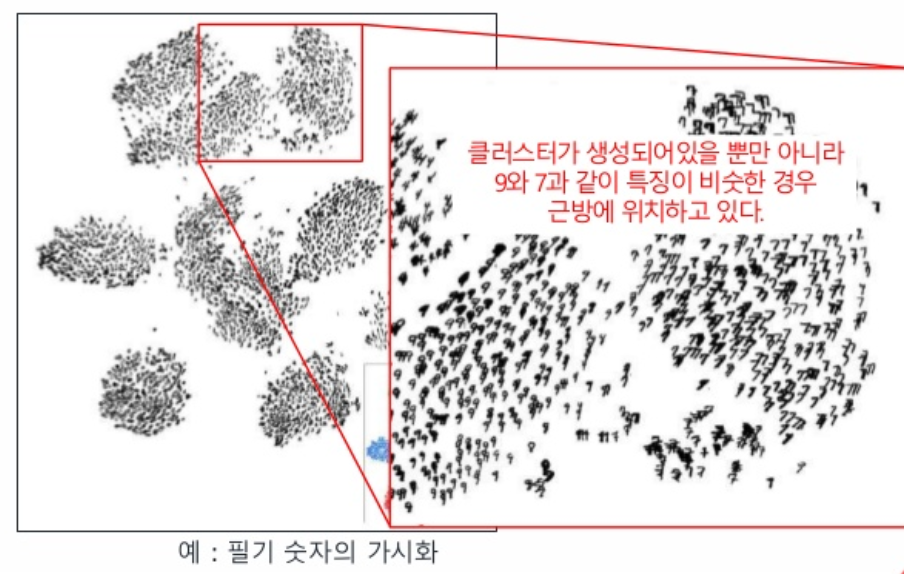
2. Stochastic Neighbor Embedding (기존의 방법)¶
Stochastic Neighbor Embedding는 Hinton et al.(2002)이 제안한 방법입니다.
2-1-1 SNE first step: similartiy of high dimensional space¶
high-dimension에서의 두 데이터 포인트 사이의 유클리디안 거리를 similarities로 변환하는 것 부터 시작합니다. 특이한 점은 similarities를 conditional probabilities 로 나타냅니다.
데이터 포인트 $x_i$와 $x_{jj}$ 사이의 similarity 는 조건부 확률 분포 $p_{i|jj}$ 가 됩니다.
(i와 j 구별이 힘들고 가독성이 떨어져 j를 jj로 표현함, j와 jj혼용하여 표시 함 j=jj로 생각하세요 ㅎ)
데이터 포인트 $x_i$는 $x_{jj}$를 이웃인지 아닌지를 가우시안 분포(조건부 확률 분포 $p_{i|jj}$)를 기반으로 판단합니다.
수학적으로 $p_{i|jj}$는 다음과 같이 정의 됩니다.
두점간 유사도 모델링에만 중점을 두었기 때문에 $p_{i|i}=0$으로 정의 했습니다.
1) 인터넷에 있는 설명 자료나 논문의 표현에서 가우시안이 계속 언급되었다.. 그래서 연속 확률 변수에 대한 확률 밀도함수라고 생각 했었는데 뒷 내용이나 표현에 대해 깊게 이해하기 힘들었다..
2) 근데 다시 생각해보니 위 식의 적분합이 1이되기는 힘들다..
3) 위 식을 각 데이터 포인트에 대한 이산확률변수의 확률 질량 함수라고 생각한다면 합이 1이된다. 즉 위 식은 각 데이터 포인트에 대한 확률질량함수이다.
4) 위 식은 xjj 가 xi와 얼마나 가까운지를 다른 데이터 포인트를 기반으로 점수를 매기는 함수라고 생각하면 편하다. 정확하게는 아니지만 일종의 softmax함수처럼 작용한다고 생각하면 편하다. xi를 기준으로 이미 뽑힌 데이터를 바탕으로 xjj가 얼마나 xi에 가까운지를 판단한다.
2-1-2 how to get sigma value: $\sigma_i$¶
$x_i$에 대한 $\sigma_i$ 값이 모두 동일할 것이라고 생각하기는 힘들 것이다.
왜냐하면 $x_i$에 대한 조건부 분포가 조밀한(dense)한 경우에는 sigma 값이 낮을 것이며
$x_i$에 대한 조건부 분포가 sparse한 경우에는 $\sigma$ 값이 높을 것이다.
perplexity는 shannon entropy에 의해 정의되는 어떤 값인데
perplexity가 높을 수록 분산이 높다고 해석 할 수 있으며 수학식은 아래와 같다.

perplexity를 5~50 사이 값으로 정하며 이는 hyperparaemter이다.
우리가 지정한 perplexity를 만족하는 $\sigma$ 을 찾으면 된다.
$perp = 2^{H(P_i)}$
이므로 생략된 $\sigma$를 넣어주면 식은
$perp = 2^{H(P_i(\sigma))}$
위식을 만족하는 $\sigma$를 구해야 하는데 이 논문에서는 처음에는 ueser가 $\sigma$ 값을 설정한후 $\sigma$값을 binary search로 찾았다고 한다
논문에서는 그냥 binary search로 찾았다고 말한 후 설명이 끝난다... ㅠㅠ 아마 아래와 같은 방법으로 $\sigma_i$를 구할 것 같다
2-2 SNE Second step: similartiy of low dimensional space¶
$y_i$는 $x_i$를 저차원 공간으로 매핑 시킨 포인트입니다. 따라서 $y_i$와 $y_{jj}$의 유사도는 $x_i$와 $x_{jj}$와 똑같아야 할 것입니다. 유사도가 같도록 $x_i$를 $y_i$로 매핑 시키는 것이 SNE 방법의 핵심입니다. $y_i$와 $y_{jj}$의 유사도는 위에서와 유사하게 다음과 같이 정의 됩니다.
또한 앞서 x에서와 마찬가지로 두점사이의 similarity모델링이 목적이기 때문에 $q_{i|i}=0$ 으로 정의 합니다.
2-3 SNE Third step: define cost function as kl divergence of two distribution¶
$y_i$가 $x_i$를 저차원 공간으로 잘 매핑 되었다면 $x_i$와 $x_{jj}$의 유사도는 $y_i$와 $y_{jj}$의 유사도와 같아야할 것입니다.
즉 $q_{i|jj}=p_{i|jj}$가 되어야 할 것입니다.
이말은 두 p와 q 두 분포가 비슷해야함을 의미하고 따라서 p와 q사이의 KL-divergence가 낮음을 의미합니다.
- kl-divergence 설명: https://brunch.co.kr/@chris-song/69
따라서 optimization을 한다면 대해서 우리가 최적화 시켜야할 식 cost function은 각 데이터 포인트 i에 대한 KL-divergence의 합으로 다음과 같습니다.
이런식으로 optmization을 한다면 아마 한 개의 데이터 포인터에 대해 전체 데이터 셋에 대한 조건부 확률을 각각 구해 $log(p/q)$를 sum해줘야 한다
2-4 SNE Fourth step : gradient decent for optimiation¶
우선 optmization해야 하는 모든 parameter는 매핑 되는 모든 점[$y_1,y_2,y_3,\cdot\cdot\cdot, y_{n-1},y_n$] 이 된다.
optmization은 stochastic gradient decent로 진핸된다.
cost function의 파라미터(매핑 되는 점 $y_i$)에 대한 편미분 식은 다음과 같다.
위 식대로 gradient decent를 진행하면 불안정하기 때문에 momentum방식으로 paraemter를 업데이트 한다.





3.1.1 nonsymetric Kl-divergence¶
기존의 방식대로 KL-divergence로 similarity를 계산하는 것에는 symetric(대칭)하지 않다는 단점이 있습니다.
위와 같은 KL-divergence식에서는 P값이 높고 Q값이 낮을때는 cost function이 높지만 P값이 낮고 Q값이 높을때는 cost function이 높아야 하지만 낮습니다.
아래 파이썬 코드를 보시면 Q = 1-P 로 표현할때 losst함수의 변화를 보실수 있습니다.
또한 2번째 그래프에서 (P,Q) 순서 쌍에 대한 loss 함수 값을 보실 수 있습니다.
P값이 낮을때 전반적으로 loss 값이 낮으며 P=Q일때 loss값이 0이 됨을 확인할 수 있습니다.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0.01,0.99,100)
y = x*np.log(x/(1-x))
plt.plot(x,y)
plt.show()

%matplotlib nbagg
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
X = np.linspace(0.01,0.99,100)
Y = np.linspace(0.01,0.99,100)
XX, YY = np.meshgrid(X, Y)
ZZ = XX*np.log(XX/YY)
fig = plt.figure()
ax = Axes3D(fig)
ax.set_title("3D Surface Plot")
ax.plot_surface(XX, YY, ZZ, rstride=1, cstride=1, cmap='hot',)
ax.set_xlabel('X(P) axis')
ax.set_ylabel('Y(Q) axis')
ax.set_zlabel('Z(loss) axis')
plt.show()

참고 문헌¶
[1] https://www.slideshare.net/ssuser06e0c5/visualizing-data-using-tsne-73621033
[2] Visualizing data using t-SNEfrom IPython.core.display import display, HTML
display(HTML())
'머신러닝' 카테고리의 다른 글
| machine learning 기초 용어 - error와 generalization (0) | 2017.10.31 |
|---|
- Total
- Today
- Yesterday
- stochastic neighborhood embedding
- SNE
- PGGAN
- 고차원
- 설명
- 배치노말라이제이션
- Ambient
- 배치 정규화
- batch normalization
- progressive growing gan
- attention gan
- 요약
- self attention
- No Free Lunch
- regularization
- 머신러닝
- high dimension
- 한글
- t-SNE
- growing
- self attention gan
- Ambient GAN
- GAN
- 정리
- internal covariate shift
- self-attention
- 한국어
- 데이터 시각화
- progressive
- Deep Learning
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |