
티스토리 뷰
Self-attention GAN¶
1. Introduction¶
1.1 GAN 소개 및 단점¶
- GAN은 성공적이였으나 일부 클래스에 대해 문제점이 있음
- GAN은 텍스처 위주 클래스(바다, 하늘 등)는 잘 생성
- 그러나 geometry가 중요한 클래스 (동물 등) 는 한계가 있음
- geometric or structural patterns 표현은 잘 못함
- 생성할 때 동물의 texture만은 실제같음
- 한계에 대한 이유
- GAN에서는 이미지의 다양한 위치에 다한 dependency를 모델링하기 위해서 convolution에 많이 의지함
- convolution의 receptive field의 범위는 local로 제한됨.
- 따라서 거리가 먼 region 사이의 dependency 모델링은 convolution layer를 몇 차례 거친 후에 가능함
- 이러한 점은 long-term dependency를 학습하는데 장애가 될 수 있음
- small model: not able to represnet dependency
- optimzation: 여러 conv layer를 거쳐 dependency를 잘 표현하는 parameter를 찾아내는데 어려움을 겪을 수 있음
- paraemterization이 통계적으로 기반이 약하고, unseen input에 대해서 성능이 떨어질 수 있음
- kerenl size 증가: 모델의 capacity가 커져서 dependency를 표현하기 쉬워질 수 있지만, convolution의 근본 목적인 계산량 감소와 통계적 효율성을 포기 해야함
1.2 Self-attention에 대해서¶
- long range dependency와 computational cost 사이의 balance가 좋음
- self attention 모듈은 적은 코스트로 각 픽셀의 전체 영역에 대한 attention vector를 만들 수 있다.

1.3 Propose¶
- Self-Attention Generative Adversarial Networks
- self attention 메카니즘을 기존 GAN에 도입함
- self attention 기존 convolution의 단점을 보완할 수 있고, 이미지에서 긴 범위와 여러 단계의 의존에 대해 모델링 할 수 있음
- GAN의 성능 향상과 관련된 최근의 insight 도입
- spectral normalization technique
- 기존에는 discrimnator에만 도입되었지만 generator에 도입함
- spectral normalization technique
2. Related Work¶
3. Method¶
- 대부분의 이미지 생성 GAN은 conv layer가 존재
- conv layer는 local neighbotr에 대한 정보를 제공함
- 따라서 conv 만으로 long-range dependency를 모델링 하는 것은 비효율적임
- non-local network 모델을 이용할 것임
3.1.1 Step1¶
- input x는 f와 g로 변환됨
- $f(x) = W_fx$
- $g(x) = W_gx$
- $W_f, W_g$는 1x1 conv로 구현
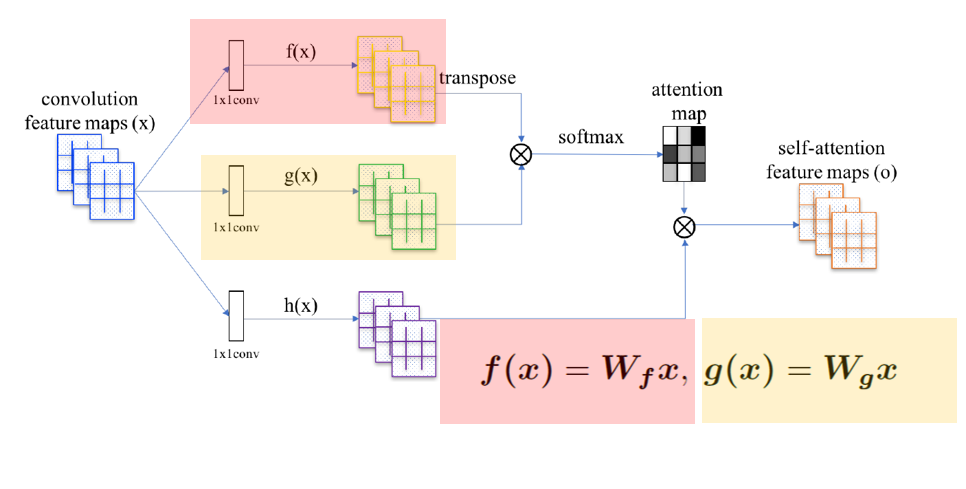
3.1.2 Step2¶
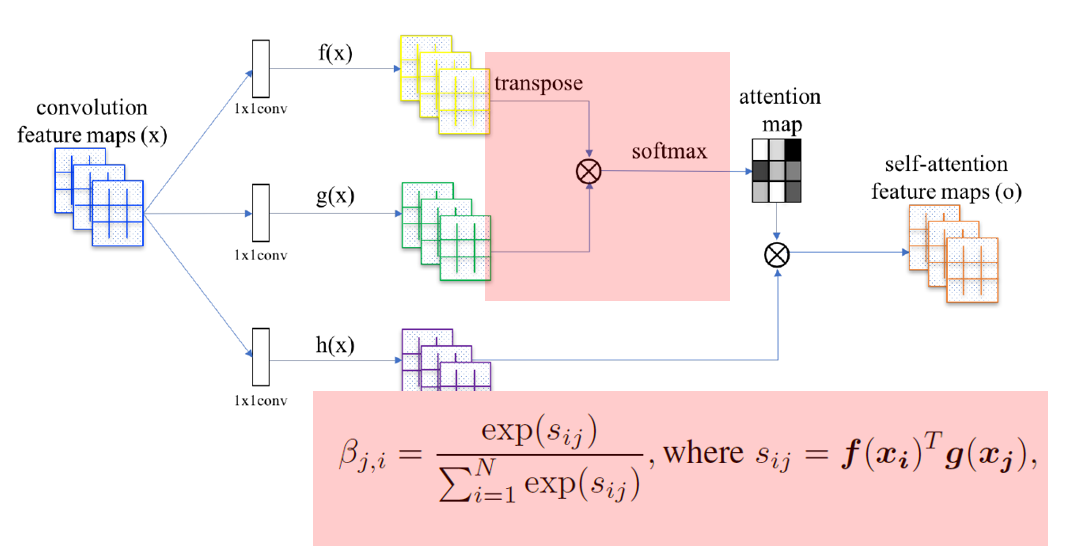
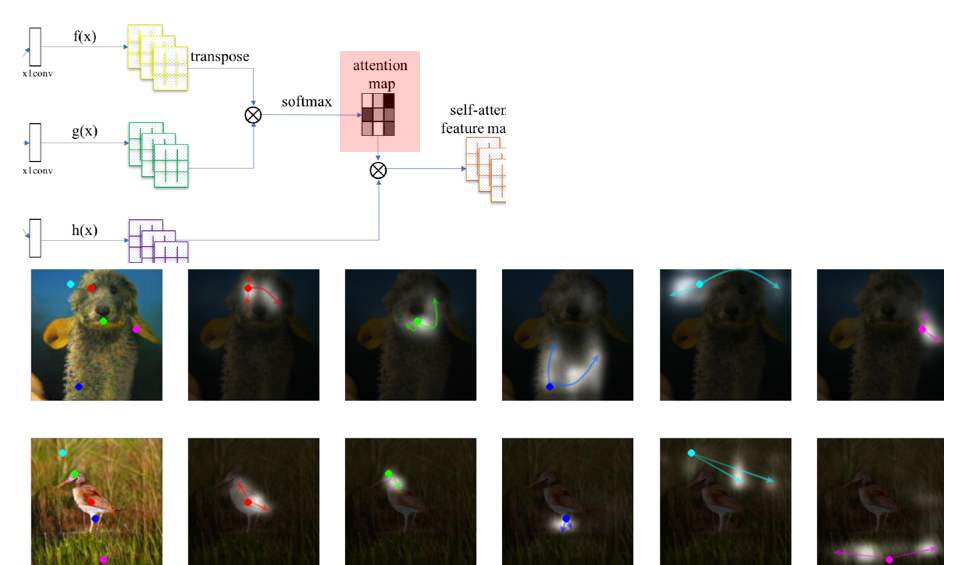
3.1.3 Step3¶
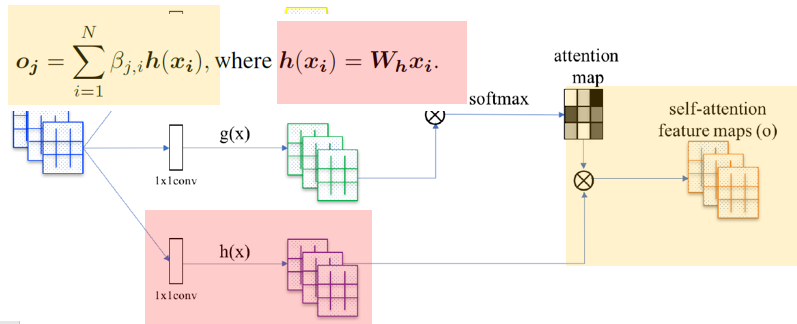
3.2 ETC¶
- $y_i = \gamma o_i + x_i$
$\gamma$는 학습 초기에는 0으로 설정
- 학습이 진행 됨에 따라 $\gamma$ 증가
- 0으로 할 경우 학습이 쉬우므로 늘려가면서 점차 학습
hinge loss 버전의 GAN loss를 사용함
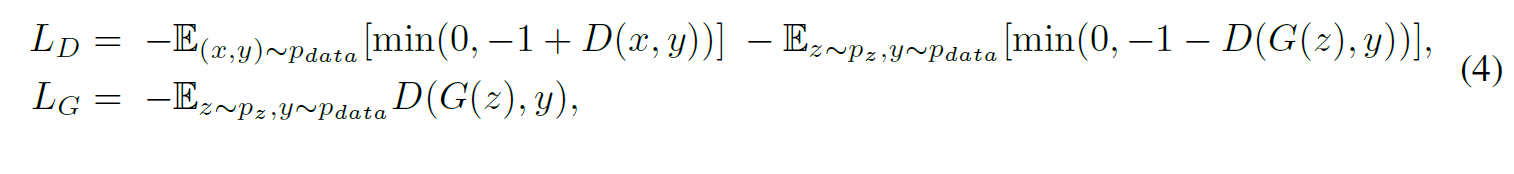
4. Techniques to stabilize GAN training¶
- spectral normalization,
- two-timescale update rule
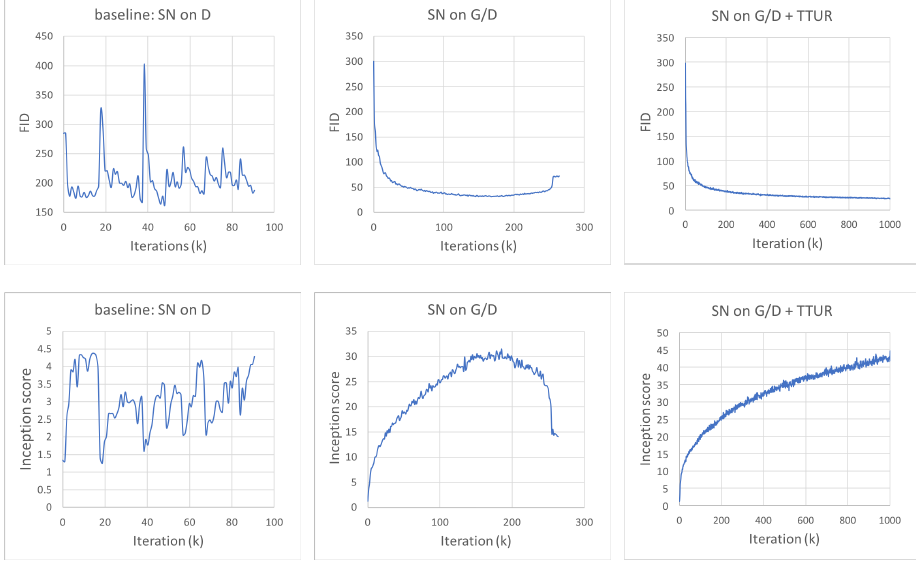
4.1 Spectral normalization for both generator and discriminator¶
- constrains the Lipschitz constant of the discriminator by restricting the spectral norm of each layer
- Spectral normalization 기법을 generator에도 적용
- Generator에 적용했을 경우 emprical하게 잘 됨을 확인
4.2 Imbalanced learning rate for generator and discriminator updates¶
- regularized discriminator는 학습이 느림
- TTUR(Two time-scale update rule for training GAN)을 사용
- Wall clock time 기준으로 더 나은 효율을 보임
5. Experiments¶
- LSVRC2012 데이터 이용
- stabilizing GAN training을 비교하기 위한 실험
- proposed self-attention mechanism is investigated
- 현재 sota와 비교
Evaluation metrics.¶
- Inception score
- Fréchet Inception distance
5.1 TTUR, spectral normalization의 효과¶
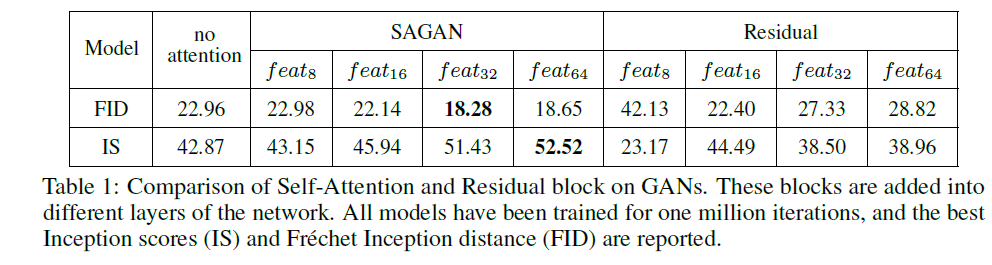
5.2 Self-attention 효과¶
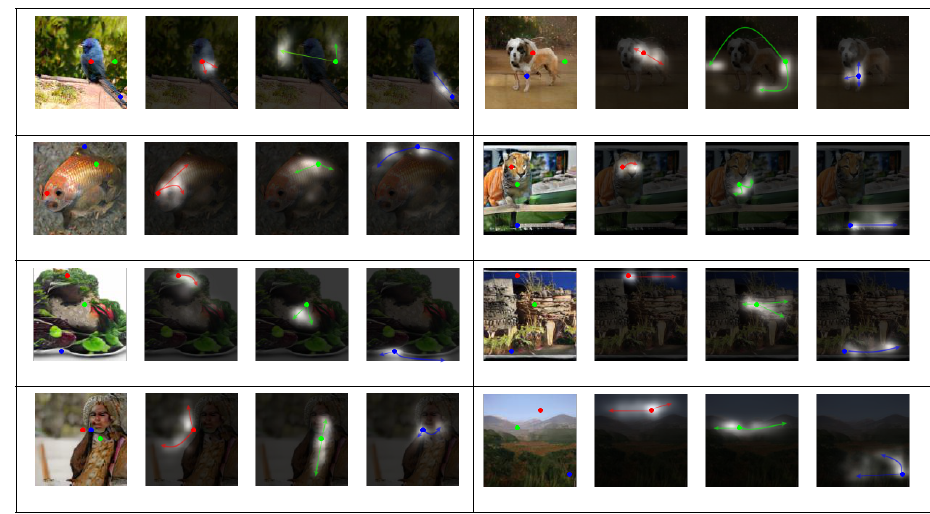
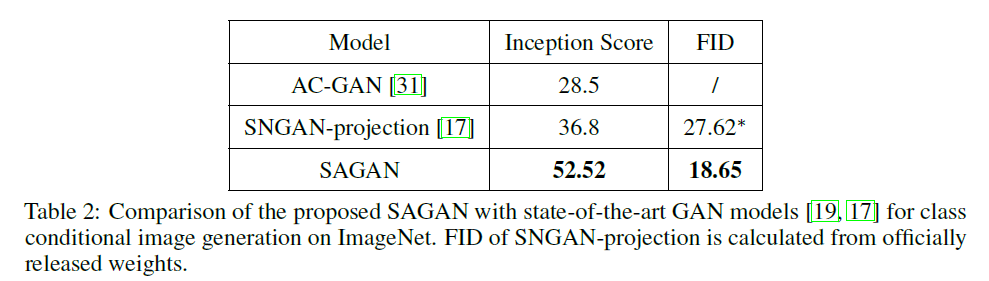
5.3 sota와 비교¶

'논문 정리' 카테고리의 다른 글
| unsupervised Image registration (비지도 이미지 정합) (0) | 2018.12.20 |
|---|---|
| Ambient GAN (불분명한 이미지에 대한 GAN) (0) | 2018.10.01 |
| Progressive Growing GAN (GAN을 저해상도부터 고해상도로 점진적으로 학습하다) (0) | 2018.09.27 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 배치노말라이제이션
- 한글
- internal covariate shift
- progressive growing gan
- self attention
- batch normalization
- 설명
- Ambient
- self attention gan
- t-SNE
- growing
- 고차원
- high dimension
- 정리
- SNE
- stochastic neighborhood embedding
- 데이터 시각화
- attention gan
- 머신러닝
- No Free Lunch
- regularization
- PGGAN
- progressive
- self-attention
- GAN
- 배치 정규화
- 한국어
- Deep Learning
- 요약
- Ambient GAN
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함