
티스토리 뷰
Progressive Growing GAN
1. Introduction¶
1-1 생성 모델의 종류¶
- 생성모델은 다양한 활용 예시를 가지고 있음
- 음성합성
- image to imgae translation
- image inpainting
요새 많이 쓰이는 3가지 모델 (각자 장점, 단점 있음)
GAN
- 장점
- sharp images
- 단점
- 작은 레졸류션에서만 가능
- limited variation
- 학습 불안정 despite recent progress
- 장점
VAE
- 장점
- VAEs are easy to train
- 단점
- 요즘 연구가 보완하긴 했지만 흐릿한 결과
- 장점
- autoregressive model
- 장점
- sharp image
- 단점
- slow to evaluate
- latent representation 없음
- directly model the conditional distribution over pixels, potentially limiting their applicability
- 장점
1-2 GAN의 한계¶
- generated distribution과 real distribution 사이에 상당한 오버랩이 없다면 gradient의 방향이 random이 될 확률이 높음
- 원래는 젠센-샤논 divergence를 사용했지만 많은 다른 방법이 나왔다.
- least square, absolute deviation with margin, Wasserstein
- 본 논문의 contribution은 기존 연구와 orthogonal 하다
- 본 논문에서는 improved Wasserstein loss, least-squares loss를 사용해 봤다

1-3-2 Contribution¶
- 저해상도부터 학습하여 고해상도까지 학습하는 점진적 학습
- 저해상도 학습 $\rightarrow$ add new layer $\rightarrow$ 고해상도 학습
- 안정적이고 매우 빠른 학습 가능하게 함
- variation을 위한 기법 추가
- variation을 유도하는 방법
- variation을 측정하는 지표 개발
- 기존에는 inception score, multiscale structural 등 있었음
- mode collapsing 방지 방법 소개
- 이러한 방법들을 다양한 데이터들로 실험해봄
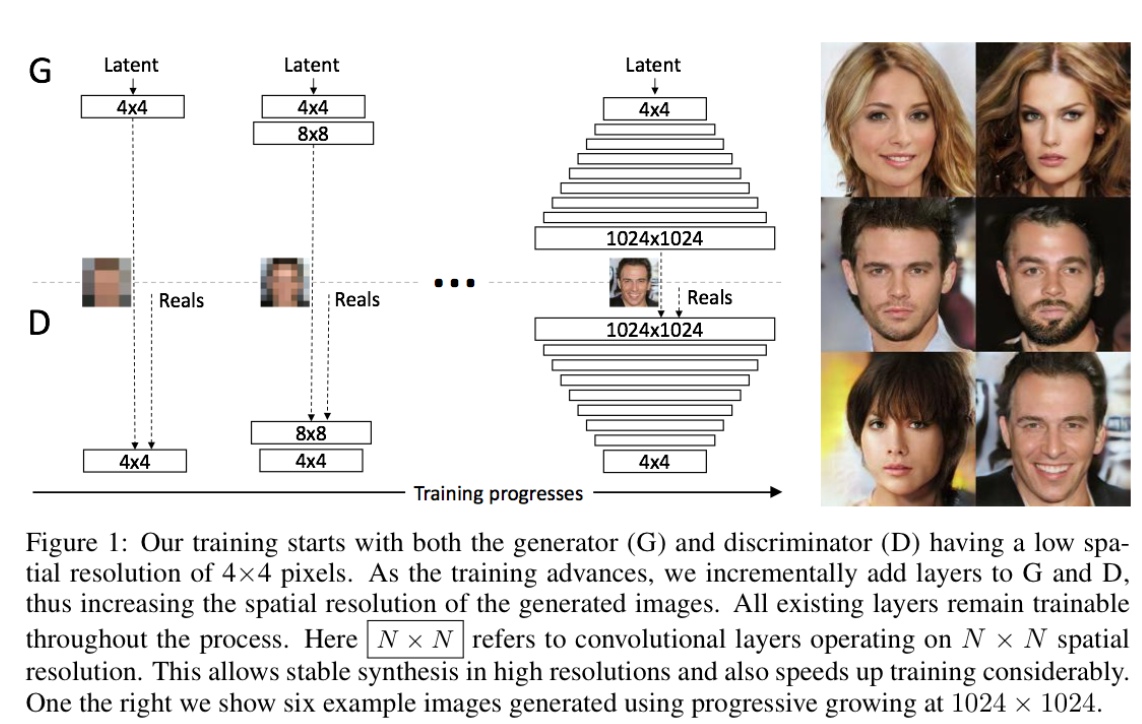
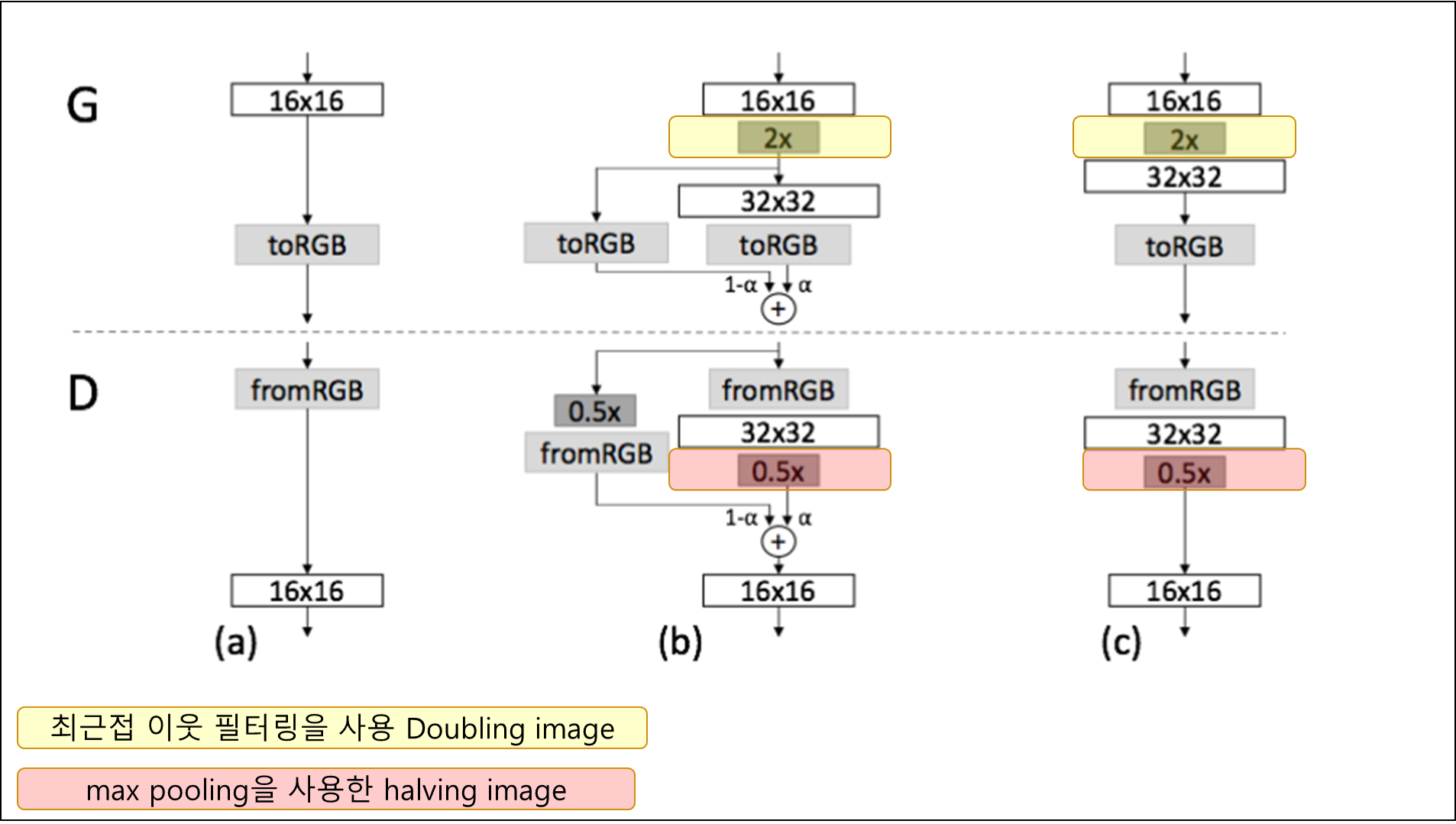
- Loop:
- $x$ 해상도 이미지를 학습함
- adding layer
- $x\leftarrow 2x$
- 고해상도로 넘어갈 때 새로운 layer를 점차 또렷하게 했다.(fade in)
- 이미 잘 학습된 low resolution network의 sudden shock 방지
- residual block과 비슷하게 작동함
- $\alpha$ 값을 점점 높여가며 학습
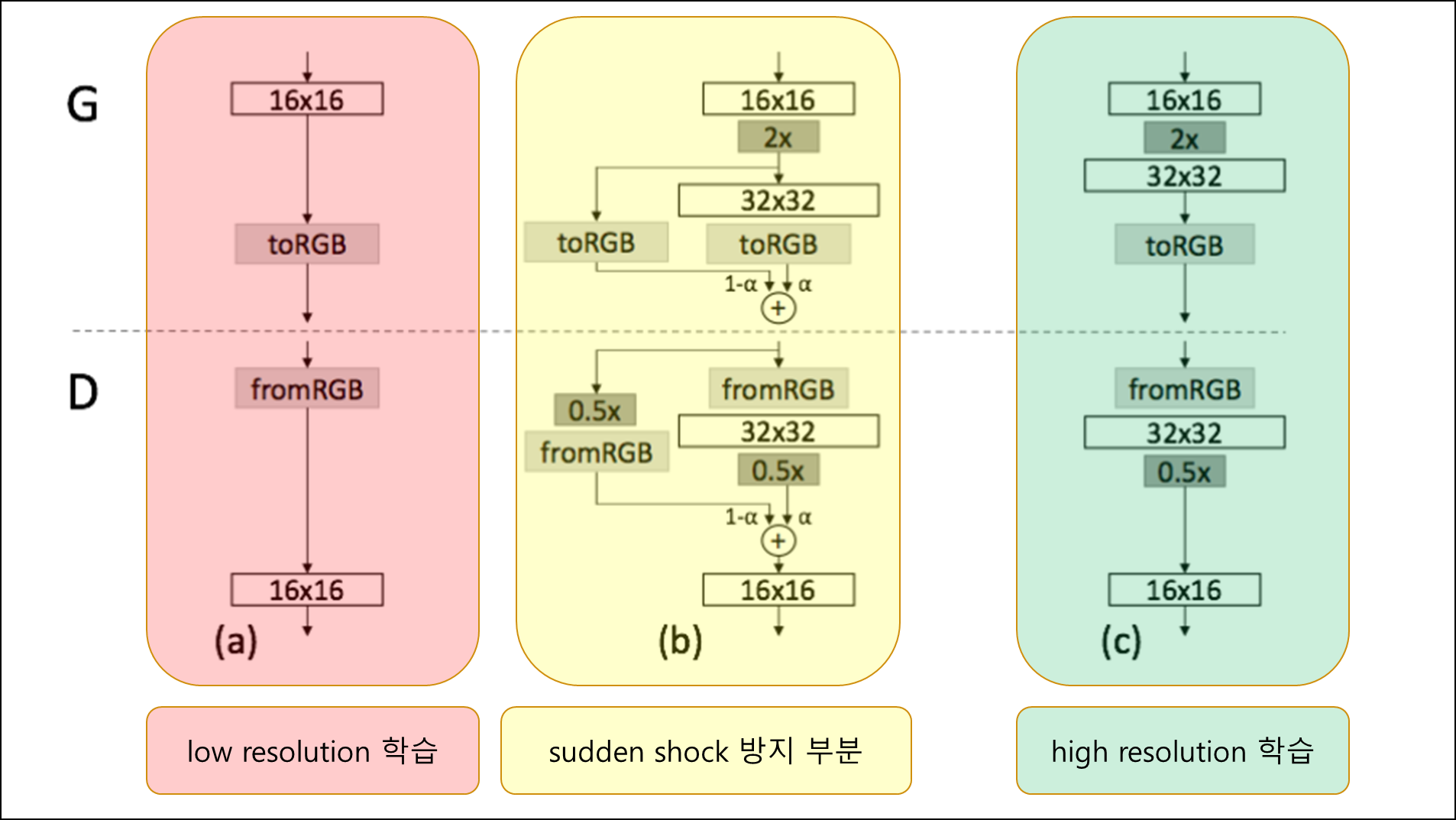
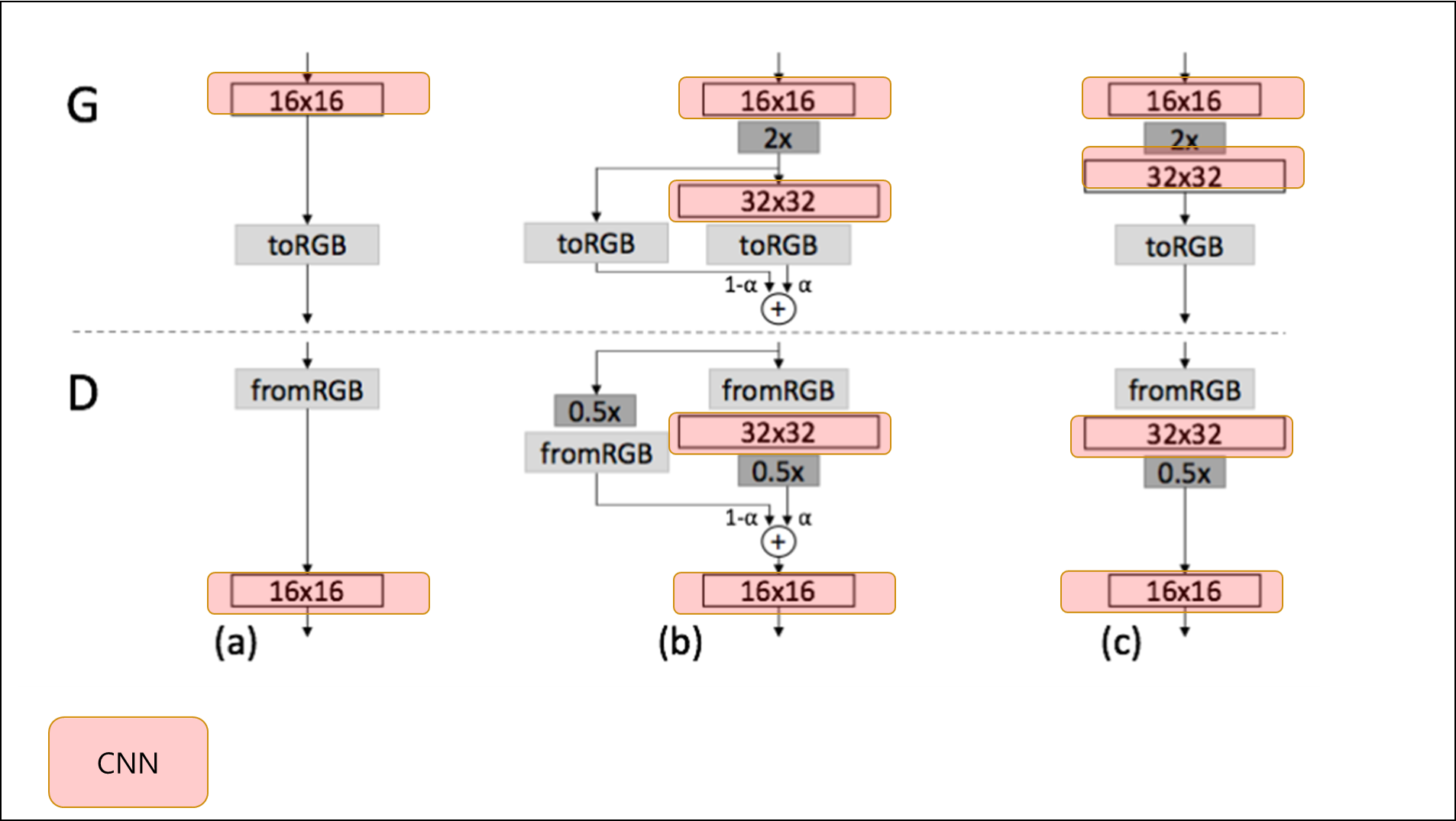
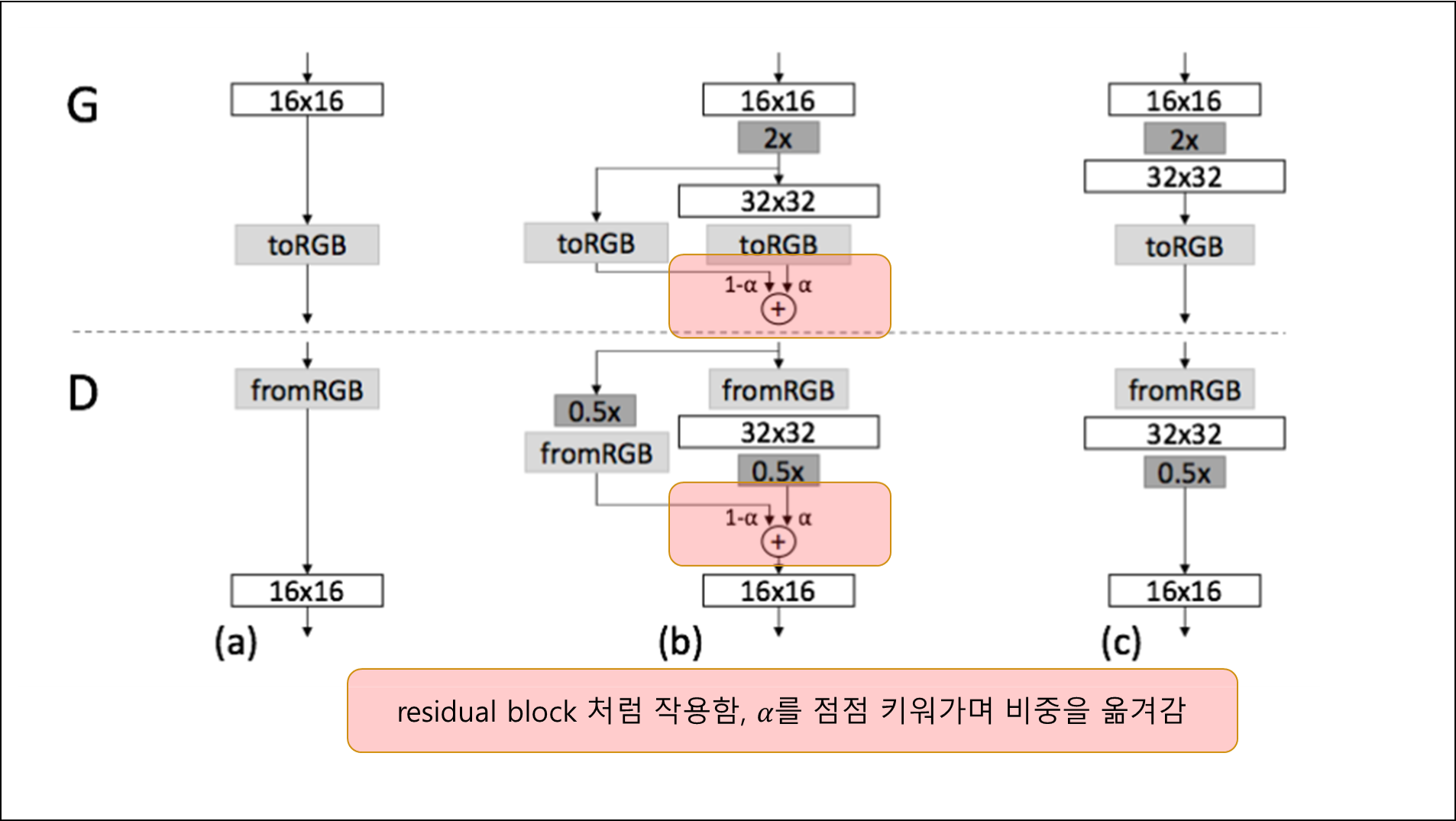

2-2 Progressive learning 장점¶
- 안정성
- 작은 이미지는 안정적 학습 가능
- class에 대한 정보가 적고 mode가 적기 때문
- 간단함
- 처음부터 바로 1024x1024 이미지를 학습하는것: 복잡한 질문
- 저해상도->고해상도 점진적 증가 네트워크: 계속해서 간단한 질문
- 빠름
- 적은 해상도에서 충분한 학습을 하게 됨
- 적은 해상도에서는 학습시간이 짧음
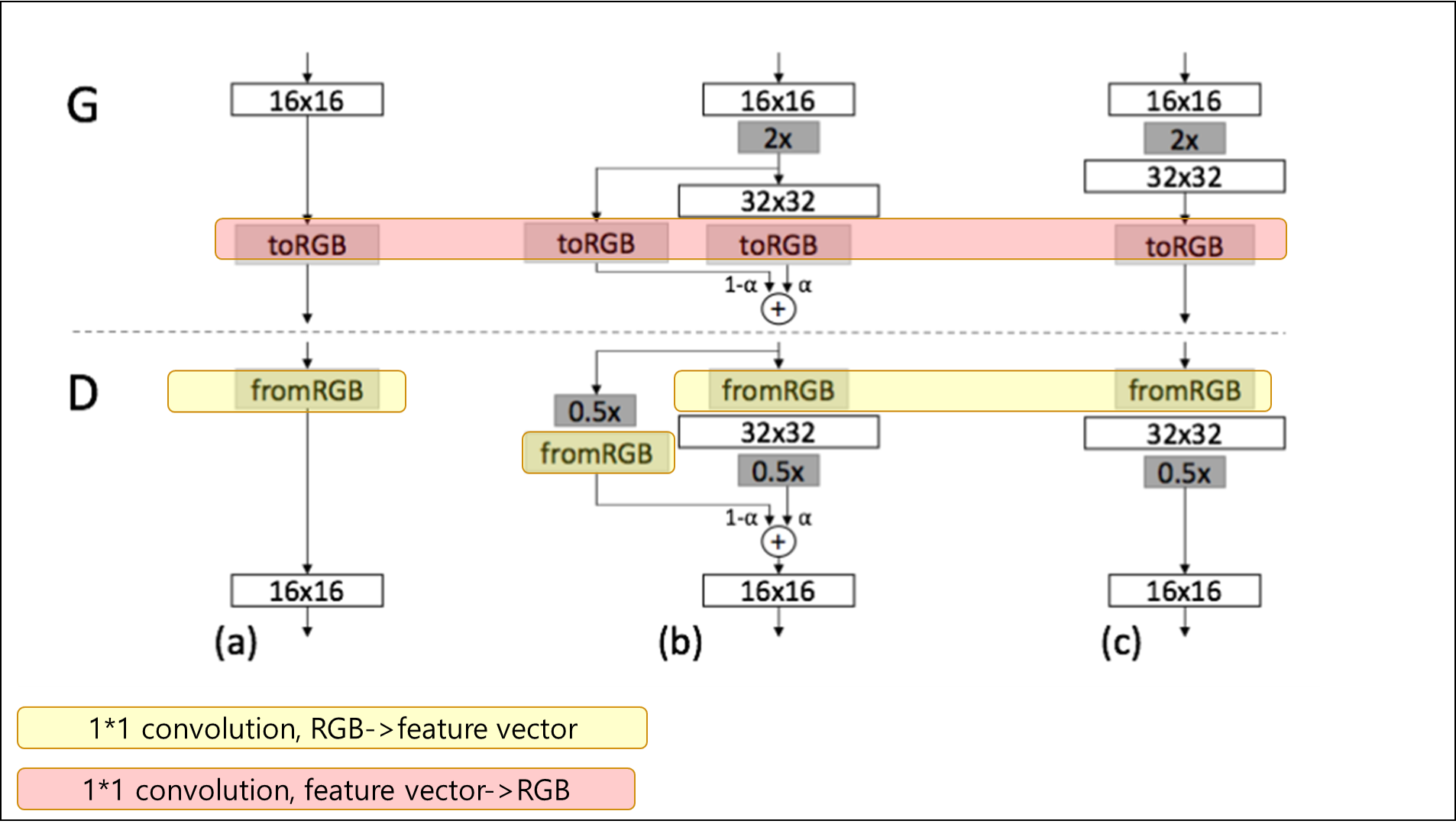
2-3 관련 연구¶
- Wang et al.(2017) 여러 해상도마다 다양한 discriminator를 사용함
- Wang et al.(2017)의 연구는 하나의 generator와 여러개의 discriminator를 사용한 Durugkar et al.(2016)에 영향을 받음
- Wang et al.(2017)의 연구는 여러개의 generator와 한개의 discriminator를 사용한 Ghosh et al.(2017)에도 영향을 받음
- Hierarchical GAN: generator와 discriminator가 각 이미지 레벨 pyramid 마다 정의
- step에 따란 학습은 똑같은
- but 오직 한개의 GAN모델만 사용함,level마다 Hierarchical GAN은 여러개 사용
- Bengio et al.(2017)의 layer wise training과 닮음
3. Increasing Variation using Minibatch Standard Deviation¶
3-1. 기존 연구(improved techniques for GAN)¶
- GAN은 training data의 variation의 subset만 알아내는 경향이 있다.
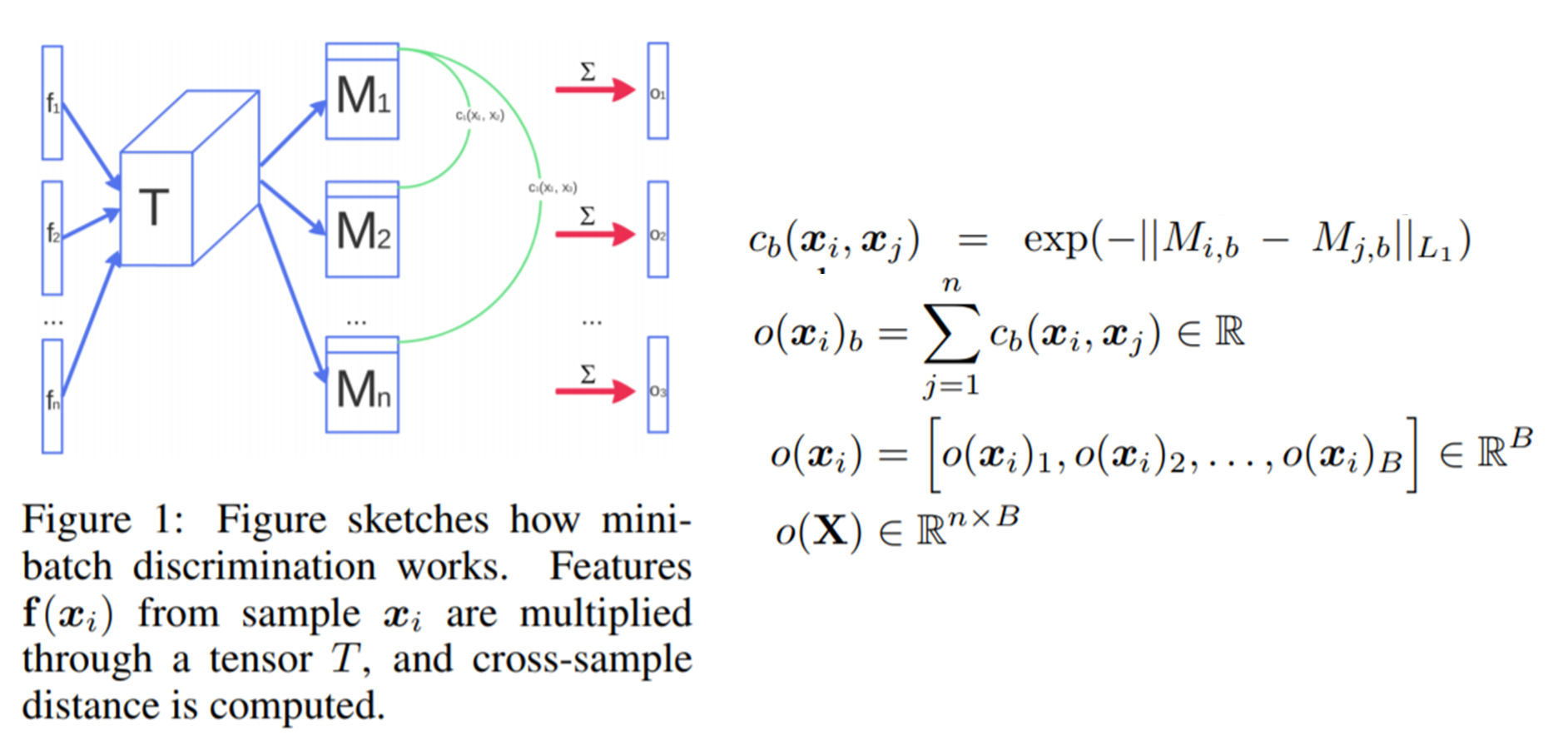
- Salimans et al.(2016)은 이 문제를 해결하기 위해 "minibatch dricrimination"기법을 제안 한다.
- 이미지 뿐만 아니라 미니 배치에서도 특징의 통계량을 계산 $\rightarrow$ 미니 배치에서도 비슷한 통계량이 나오도록 유도
- 미니 배치 layer 추가로 구현함
- discriminator의 중간 layer 특징 : $f(x_i)$ 를 학습되는 큰 텐서 $T$와 곱해 vector로 사영시킴
- 이러한 벡터들을 이용한 통계량을 미니배치안의 각 관측치마다 적용하여 concat해서 다음 layer로 넘김
3-2. 기존 연구보다 좋은 방법 개발¶
- 학습해야하는 parameter 없음
- 추가적은 hyper parameter 없음
- 각 미니 배치의 중간 layer의 특징의 각 spatial location에서의 standard deviation 계산
- 특징의 각 spatial location마다 계산된 값 concat
- 이러한 layer는 dicriminator의 어느 layer에도 넣을 수 있음
- 그러나 마지막 layer에 사용하는게 가장 효과가 좋았음
3-3 다른 연구들¶
- 미니 배치 정보를 discriminator에 넣어주는 것이 좋다는 것을 증명함
- unrolling GAN (update regularize)
- repelling regularizer (generator에 새로운 loss term 추가)
- 이러한 방법들이 본 논문의 방법보다 나음을 인정함..ㅎㅎ
4. Normalization In Generator And Discriminator¶
- GAN은 generator와 discriminator의 unhealthy한 경쟁으로 인해 siginal magnitude가 점차 증가하기 쉬운 것이 증명이 되었다.
- 배치노말라이제이션의 변형이 제안됨
- 본래 batch 노말라인제이션은 covariance shift를 없애기 위해 제안되었지만,
- GAN에서는 이러한 현상 관찰하지 못함
- 실직적으로 GAN에게 필요한 것은 signal magnitude와 경쟁을 조절하는 것으로 파악됨
- 학습할 parameter가 필요없는 2가지 방법을 제안
4.1 Equalized learning rate¶
- simple하게 weight를 표준 정규분포에서 뽑음 (N(0,1))
- 대신 dynamic하게 학습중 scale을 해줌
- Kaiming he initializer
$\hat w_i= w_i/c$, c: He initializer constatnt

4.2 Pixcelwise feature vector normalization in generator¶
- 나선형으로 돌아가면서 학습하는 것 방지
- local reponse normalization 의 변형
- $b_{x,y}=a_{x,y}/\sqrt{\frac{1}{N}\sum_{j=0}^{N-1}(a_{x,y}^j)^2+\epsilon}$
- a: original feature vector
- b: normalized feature vector
- generator의 성능에 나쁜 영향거의 없음
- signal magnitude 문제를 해결
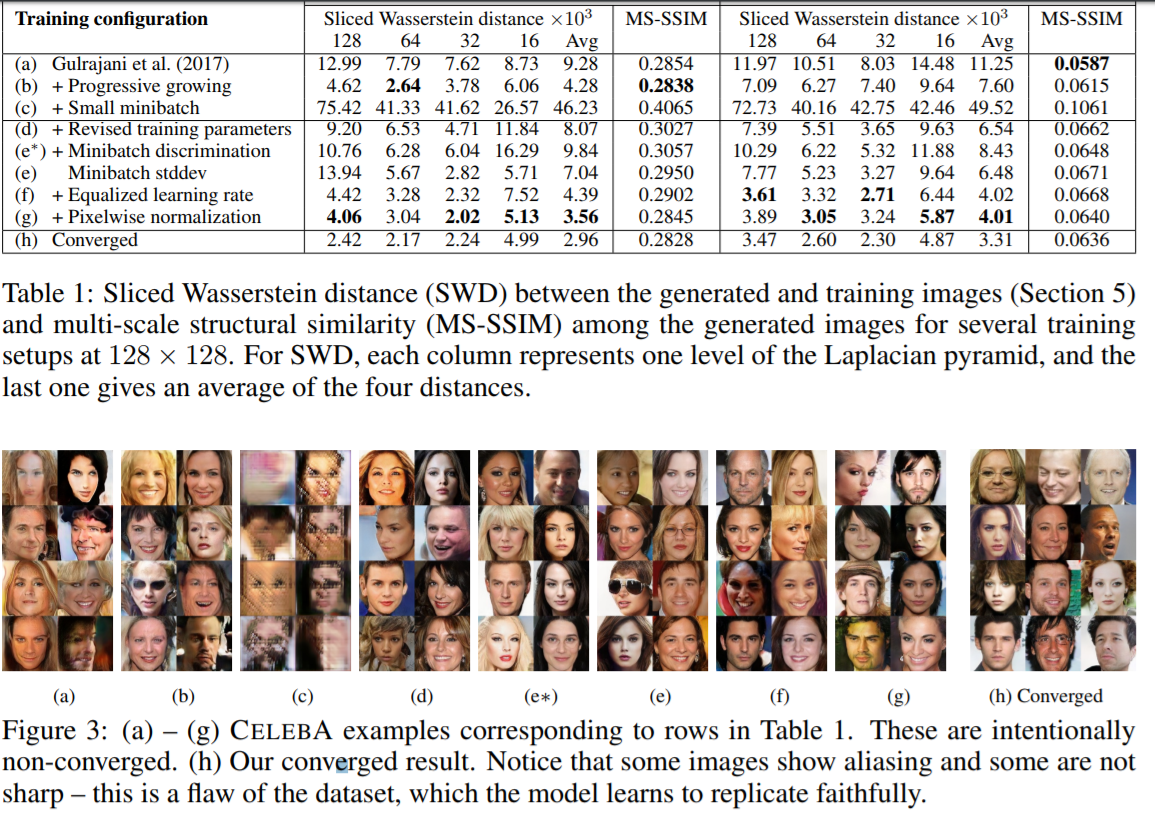
5. Multiscale statistical similarity for assessing GAN results¶
- MS-SSIM *
6. Results¶


'논문 정리' 카테고리의 다른 글
| unsupervised Image registration (비지도 이미지 정합) (0) | 2018.12.20 |
|---|---|
| Ambient GAN (불분명한 이미지에 대한 GAN) (0) | 2018.10.01 |
| Self attention GAN (self attention을 gan에 적용하다) (0) | 2018.09.20 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- batch normalization
- PGGAN
- self attention
- stochastic neighborhood embedding
- Deep Learning
- progressive
- Ambient
- SNE
- self-attention
- 요약
- 한국어
- 배치 정규화
- self attention gan
- high dimension
- Ambient GAN
- No Free Lunch
- growing
- progressive growing gan
- 정리
- attention gan
- 한글
- t-SNE
- 배치노말라이제이션
- 설명
- 고차원
- 데이터 시각화
- regularization
- GAN
- internal covariate shift
- 머신러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함