
티스토리 뷰
Ambient GAN¶

1-2 GAN¶
- GAN: 암시적 모델에서 뛰어난 성능 보여줌
- geneartor: low-dimensional input -> high-dimensional learned distribtion
- disciminator: generator의 결과가 진짜인지 가짜인지 판단
- 둘사이의 min-max game
1-3 GAN의 한계¶
- 학습하고자 하는 분포로부터 완전히 관찰된 매우 많은 양의 학습데이터 요구
- 이러한 요구는 매우 값비싸고, 특정 영역에서는 불가능 할 수 있음
1-4 문제의 해결¶
- 이러한 문제를 noisy, incomplete한 데이터로부터 바로 학습하는 방식으로 풀었음
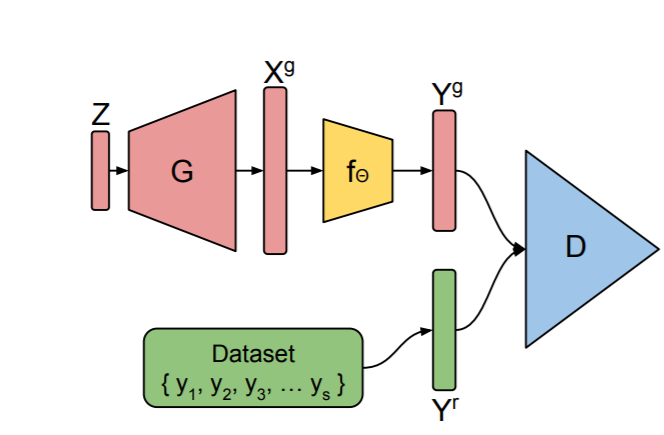
- 매우 중요한 가정은 measurement process를 완전히 아는 것
- measurement
- (실제 본질) ---관측---> ( 변형 )
- 관측으로 인한 변화를 알고 있다는 가정
- 즉 실제 본질을 가지고 있을때 관측 process를 시뮬레이션 할 수 있음
- gan 처럼 바로 데이터가 가짜인지 진짜인지 판단
- genrator가 한번 생성한 데이터를 measuremnt 프로세를 거쳐서 판단
- 노란색 $f_{\Theta}$ 가 measurement 임
1-5 이론적 결과¶
- measurement : noisy, blur
- 1) gaussianl kernle로 컨볼루션
- 2) 각 픽셀마다 independent gaussian nosie
- 각각 이미지는 노이즈 때문에 다시 역으로 복원 불가능 (역함수 없음)
- 하지만 특정 measuremnt로 부터 나오는 변형된 분포를 결정하는 원래 분포는 unique함을 보였다
- r->m->t, r: 원래 분포, m: measurement, t: 변형된 분포
- 각각의 이미지는 복원 불가능 하지만 분포는 역함수 존재 (r이 unique함)
1-6 경험적 결과¶
- 이론적으로 분포 복원이 가능한지 증명 안된 measurement에 대해서 실험
- fig.2: occulusion
- fig.3: Wiener deconvolution
- fig.4: 2차원 mnist 데이터를 1차원으로 projection

2 Notation and approach¶
2-1 Notation¶
- $r: real\ distribution,\ true\ distribution$ (실제 분포)
- $g: generated\ distribution$ (만들어진 분포)
- $y: measurements$ 관측치(변형된 이미지)
- $x: underlying\ space$ (기저 공간?)
- $p_x^r: real\ underlying\ distribution\ over\ R^n$ (기저 공간에서의 실제 분포)
- $n: size\ of\ underlying\ space$ (기저 공간 차원)
- $m: size\ of\ measurements$ (관측치의 차원)
- $f_\theta:\ R^n \rightarrow R^m$, measurements is output of fucntion $f_\theta$ parameterized by $\theta$ (관측으로 인해 생기는 변형 함수)
- $\theta:$ paraemter of measurements function $f$ (변형 함수의 매개변수)
- $f_\theta$는 랜덤성을 가져야 함 따라서 $\theta$를 확률 변수로 설정
- $\Theta \sim p_\theta$, $p_\theta$는 $\theta$의 확률 분포
- $y = f_\theta(x)$
- $p_y^r$: measurements의 실제 분포
- $ (p_x^r,\ f,\ p_\theta )\ \rightarrow\ p_y^r$
- 실제 데이터 분포, measurements 함수, 함수의 매개변수 분포가 관측 데이터의 분포 결정
- if $X \sim p_x^r$ and $\Theta \sim p_\theta$, then $Y= f_{\Theta}(X) \sim p_y^r$
2-3 notation about idea¶
- $Z \in R^k,\ Z \sim p_z$, 잠재 변수 분포
- $G: R^k \rightarrow R^n$, generator
- $X^g = G(Z)$
- $X^g \sim p_x^g$
- $Y^g = f_\Theta(X^g) = f_\Theta(G(Z))$
- our goal = learn generator G such that $p_x^g$ is close to $p_x^r $
3. Measurements Models¶
3-1 Block Pixels¶
p 확률로 각 픽셀이 독립적으로 0으로 바뀜
3-2 Convolves + Noise¶
컨볼루션+노이즈 $k*x+\Theta,\ k=convolution\ kernel,\ \Theta=noise$
3-3 Block-Patch¶
랜덤으로 선택된 k * k 크기의 패치가 0으로 바뀜
3-4 keep-Patch¶
랜덤으로 선택된 k * k 크기의 패치를 제외하고 모두 0으로 바뀜
3-5 Extract-Patch¶
랜덤으로 선택된 k * k 크기의 패치만을 사용 (location 정보 없어짐)
3-6 Pad-Rotate Project¶
zero pad 후 랜덤한 각도로 회전 수직선으로 projection 함
3-7 Pad-Rotate Project $theta$¶
zero pad 후 랜덤한 각도로 회전 랜덤한 각도의 선으로 projection 함
3-8 Gaussian-Projection¶
랜덤한 가우시안 벡터로 projection $f_\Theta(x) = (\Theta, \langle \Theta, x\rangle)$
4. Theoretical Results¶


5. Baseline¶

6. QUALITATIVE RESULTS¶

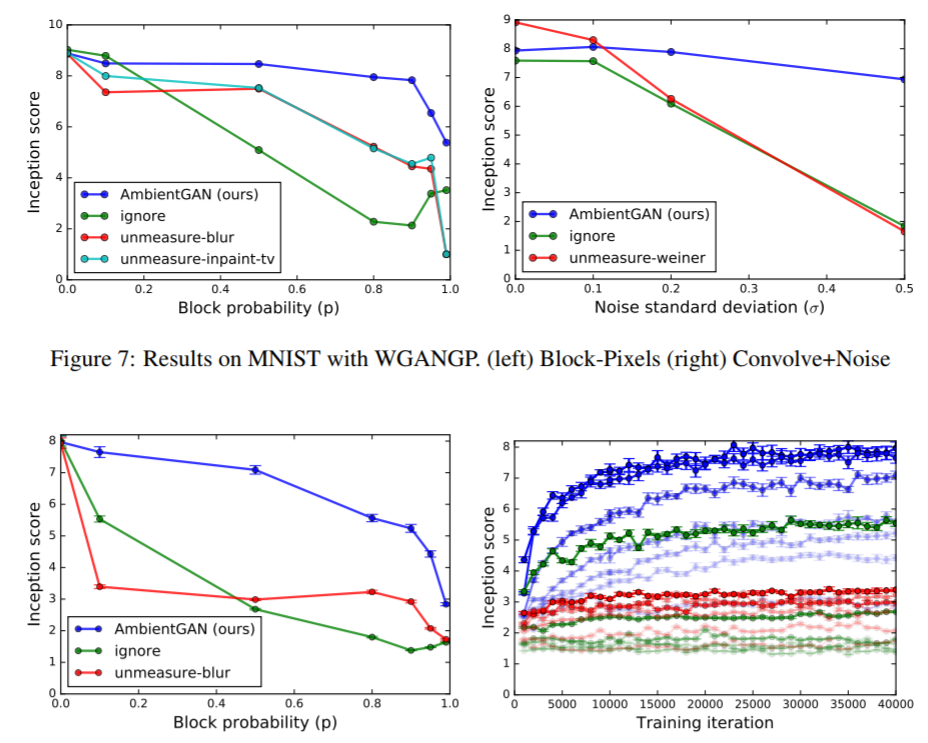
7. QUANTITATIVE RESULTS¶
'논문 정리' 카테고리의 다른 글
| unsupervised Image registration (비지도 이미지 정합) (0) | 2018.12.20 |
|---|---|
| Progressive Growing GAN (GAN을 저해상도부터 고해상도로 점진적으로 학습하다) (0) | 2018.09.27 |
| Self attention GAN (self attention을 gan에 적용하다) (0) | 2018.09.20 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 고차원
- progressive
- 데이터 시각화
- regularization
- GAN
- attention gan
- self attention
- internal covariate shift
- PGGAN
- 한글
- Ambient
- 머신러닝
- No Free Lunch
- high dimension
- 배치노말라이제이션
- Deep Learning
- 설명
- 한국어
- 배치 정규화
- t-SNE
- 정리
- self attention gan
- batch normalization
- self-attention
- Ambient GAN
- growing
- progressive growing gan
- SNE
- 요약
- stochastic neighborhood embedding
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함